Science, a Conversation
Sunny is an economist who designs randomised control trials. Tom is a post-doc who researches the impacts of climate change. They are a married couple, and inevitably their conversations sometimes turn to how science could be improved.
Recently, that question has become harder to avoid. Some of Tom's research helped trigger the high-profile retraction of a Nature paper, an experience that exposed just how badly modern science handles the messy reality that conclusions sometimes need to be revised. Meanwhile, the Trump administration has slashed federal research funding. All the while a surge of AI-generated papers is beginning to swamp an already overburdened peer-review system. Each development points in the same direction: the institutions of science are showing their age.
What follows is a conversation about what comes next. New technology has made it possible to imagine science organised less like a lecture and more like a conversation: open, iterative, and always unfinished.
Sunny: Tom, I was telling my friend the other day that I just finished my PhD in economics. Of course when she heard that, she started asking about investing advice, what's happening with oil prices, the rate of inflation. I smiled and mumbled something, but the honest answer is: I don't know anything! But I CAN say a lot about the statistics regarding people's beliefs about air pollution in Jakarta. Like all scientists, I had to specialize in my PhD. In fact, to be a scientist today is to be a specialist.1 It's pretty incredible really — humanity has created so much knowledge that any one person can only know a tiny sliver of it.
But this does create a problem. If only insiders can seriously interrogate the assumptions, methods, and judgments of scientific knowledge, science becomes opaque to everyone else. And how can people value what they can't access? We're watching this play out right now in the second Trump term, with sweeping cuts to federal research funding. Clearly a lot of people see research funding as a waste of resources, not a public good.
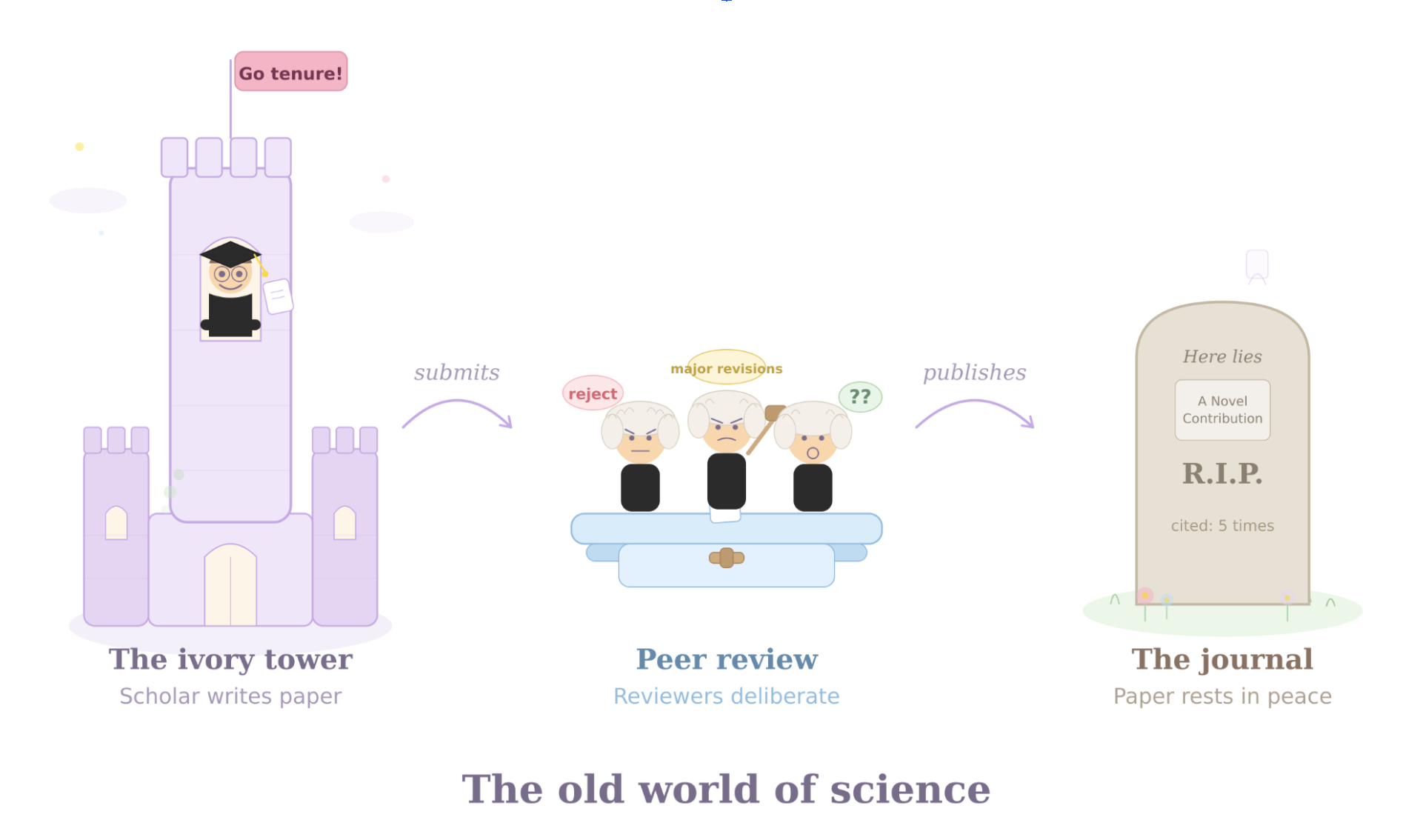
Tom: I think that the current publication process hardens that divide. Once a paper is published, busy scientists (like me) have no incentive to revisit old analyses. Journal publications are the way we get judged by our peers, and as soon as one paper is published we move on to the next one. Our work becomes static and frozen even as science moves on around it.
There used to be a reason for that; the scientific process used to move through print. If you print a journal and send it out into the world, and then later decide that the results or their interpretation should change, you can't hunt down each copy and update it.
Sunny: Encyclopedias used to work in the way that academic research does now. A small group of experts wrote entries, and everyone else consumed them. Britannica was the gold standard for two centuries, printed in books that salesmen would knock on your door to sell.
But then Wikipedia came along and flipped the model! Now anyone could contribute, anyone could challenge what was written! For sure it was chaotic at first (and still is!). And yet what emerged was more comprehensive, more current, and more self-correcting than what the experts could build alone. Of course expertise still matters, but Wikipedia proved that useful knowledge can emerge from a bunch of deeply curious, dedicated nerds.
Tom: A new technology could lead to a similar revolution in academic research. AI tools can now translate the specialized language of any academic field into prose that a non-specialist can critically engage with. A curious reader no longer needs a Ph.D. to ask whether a paper's assumptions are reasonable, to trace the logic of its argument, or even use AI to reanalyze or simulate its data using different methods. For the first time, we can imagine reversing the one-way flow from expert to public.
Imagine a platform, call it Scientific Conversations, where any working paper, published article, or scientific claim becomes a site of open, structured discussion. Users replicate code and report what they find. They test how the results change under alternative assumptions. They annotate passages, add case studies, and supply the context of their lived experience. The aim is to create a synthesized, evolving companion to the original paper. It is not a replacement, but a living annotation layer that makes the paper's logic legible and contestable by anyone willing to do the work.
Sunny: Oh and you know I was raving about this article on X's Community Notes. This is X's way of letting users flag and add context to potentially dodgy posts. We can totally take lessons from their bridging algorithm for building consensus. The algorithm first asks users to rate whether a note is helpful or not, and then looks at the rating histories of those users. Notes get upranked when the people rating the notes as helpful are folks who normally disagree with each other. The logic is that if people who normally disagree can actually converge on something, it's probably pretty accurate. What's really interesting is that people trust these notes much more than they trust X's top-down misinformation flags.
We could apply the same principle to scientific discussion, where contributions gain visibility by earning credibility across researchers and readers with different priors!
I'm loving this vision, because human judgment isn't being replaced. Even with all the AI hype, it's not a magic wand. There was actually a major DARPA-funded effort trying to use AI to predict which research would replicate — and it just couldn't do it reliably. Human judgment remains key to scientific credibility. AI just lets us bring more people to the table.
Tom: Scientific Conversations would disrupt every part of the research process. Currently, researchers submit papers to journals; 2-3 people peer review their paper. If the journal decides to publish their paper, it is frozen into the scientific record, and rests in the mausoleum of the journal website. Other scientists only visit to pay their respects. Our idea would change that.
Sunny: It's interesting because for an outsider looking in, papers look so permanent. But we know from being inside the research process that the academic literature at any one time is always so provisional. Results are fragile. Assumptions crack. Methods improve. Consensus shifts. No scientist believes that any one paper contains the last word, it is a stepping stone that allows the field as a whole to move forward. But for anyone outside the field, it is hard to see any of that movement.
Tom: When an error is serious enough to force the issue, the system falls to a blunt tool: retraction. That turns correction into a kind of public trauma. The wider public, encountering only the final drama, mistakes a technical correction for proof that science itself cannot be trusted. Incentives to correct the scientific record are small, and complicated by personal relationships and career incentives.
I know this firsthand. I was the first author on a critique that contributed to the retraction of a landmark paper in climate economics. The paper had made a striking claim about the scale of future economic damages from climate change. When I reanalyzed it, I found that its headline result did not replicate. What followed was long, technical, and personally difficult: rounds of review, deliberation, and then, once the retraction came, a wave of public distortion. A technical correction was turned into a political story. Some people treated it as evidence that climate science itself was unreliable, which is the exact opposite of my view.
Sunny: I mean there have been some heroes who do replications and help update the scientific record, and large-scale replication projects have made really substantial progress. But the tough thing is that replication is still undervalued in a system that rewards novelty. Asking the academic establishment to reform itself means asking people to dismantle the incentive structures that built their careers.
What we're proposing here is to instead try a crowd-sourced, bottom-up approach that invites people outside the field. Invite people who aren't constrained by the academic incentives. Invite people who wouldn't feel embarrassed or scared to give open feedback to people they might run into at a conference!
Tom: For research that is cutting-edge, shifts priors, or carries large policy stakes, two or three peer reviewers are often too thin a stress test. We would not want to replace peer review; expertise still matters, and editors need it. But we can complement it. Imagine a working paper that begins a conversation, by being uploaded to the Scientific Conversations platform alongside its code and data. Users replicate the study, annotate it, or add context from their experience. Journal editors receive not only traditional referee reports, but also a structured signal from a broader community: what held up, what broke, and where the real points of disagreement lie.
Sunny: That actually matters even more now, because the research system is under growing strain. Editors and reviewers were already grappling with overload and reviewer fatigue, and now we have generative A.I. that's making it easier to produce papers. A platform that crowdsources part of this process wouldn't eliminate the need for expert review, but could help focus scarce expert attention to the questions that most need it.
There's kind of already an analogue in my own field. My job is to design and run randomized controlled trials (RCTs). An awesome innovation has been RCT registries, which allow researchers to pre-register their analysis. They basically make it much harder to go hunting for significant results after the fact and pretend that was the plan all along. For example, all of my trials have been pre-registered on these sites before fieldwork begins. And I honestly love it. I'm such a scatterbrain, so thank god this registry forces me to think clearly before the chaos of fieldwork starts. I commit to an analysis plan before I see the data, knowing that another researcher will compare my final paper against that plan a year from now. Of course, in practice, things change when I'm running the experiment. But it's great that pre-registration forces me to explain my decision-making process and explain why the analysis diverged from the original plan. That gap between what I planned and what I did becomes itself a research output.
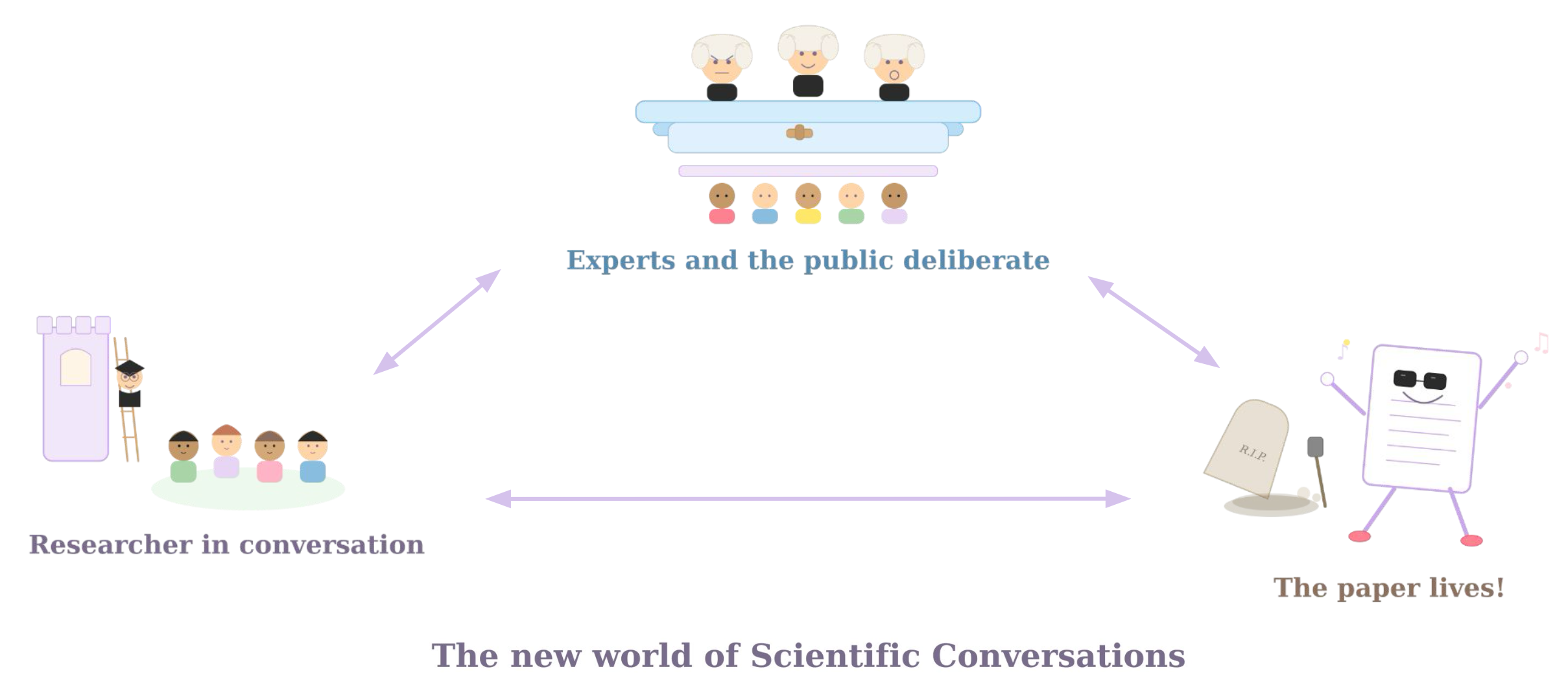
Tom: Scientific Conversations will incentivise researchers to produce better research, leading to more trust in the research system. The process will improve research by imbuing a norm of transparency and replication. You publish your code knowing someone will run it. You document your assumptions knowing someone will test alternatives. Transparency becomes the default.
But the point of Scientific Conversations is not adversarial, but to recognize mistakes, uncertainty, and context as a natural part of the scientific process. The goal is dialogue. Papers could have multiple editions, with credit given to those who extend or improve them. The research endeavour, refocused onto conversations and away from papers should incentivise a more dynamic, truthful form of science.
Sunny: Parts of this future already exist. Open access to code and data is great and more institutions are requiring it. But open access alone doesn't give anyone the means to actually challenge assumptions or test methods.
Tom: And large-scale replication projects have shown how much value there is in organized scrutiny. Some replications uncover errors, but others reveal something subtler. Results are often found to be contingent on modeling choices or assumptions that other researchers could reasonably have done differently. That distinction matters. The public should be able to see not just whether a result "replicated," but why it did or did not.2
Sunny: A conversation could begin anywhere there is already a paper, data, and code! Many journal articles already point readers to its materials. A conversation layer could simply begin there.
Tom: The core claim behind Scientific Conversations is simple: motivated experts and non-experts alike, equipped with A.I. tools, can engage meaningfully with published research.
Sunny and Tom: Let's test it! Recruit participants without specialist training in the relevant fields. Select published papers across a range of disciplines, each with publicly available materials and methods. Give participants access to A.I. tools and to a platform where they can ask questions, annotate arguments, rerun code, test assumptions, and discuss what they find. We'd need to pilot the rules of engagement and moderation, though we can learn from existing systems like Wikipedia and Community Notes.
Then watch what happens. Do participants cluster around certain papers? Do they raise methodological questions, rerun analyses, or challenge assumptions? Do authors engage? For papers without open data, can there still be fruitful discussions without full replication? Does the discussion converge on something useful, or dissolve into noise? A panel of experts could then assess whether the resulting conversations surfaced insights that would genuinely help the authors and editors.
Notes
- Small disclaimer: 'scientist' here means professional researchers of all stripes, social scientists included. Objections will be politely noted and ignored. ↩
- Examples include the Reproducibility Project, Systematizing Confidence in Open Research and Evidence, i4Replication, and recent publications. ↩